ARM releases the latest Compute Library
I have been so happy for so many days, the "heart" has worked hard, just as Arm has a good news to tell you that the latest season of the Compute Library public release (version 17.9) is now available, let us take a look at the key new Add some features and functions.

This release mainly adds the following features:
Multiple new machine learning functions for Arm CPU and Mali GPU
Support for new data types and precision (emphasis on supporting low-precision data types)
Support for FP16 acceleration with new instructions for the Arm-v8.2 CPU architecture
Microarchitecture optimization for key machine learning functions
Memory management tool that reduces complex network memory overhead
Infrastructure framework for basic testing
New functionWe've added a number of new functions to meet the needs of developers targeting Arm-based platforms. These new routines are written in OpenCL C and C (using NEON Intrinsics).
OpenCL C (for Mali GPU):
Bounded ReLu
Depth wise convolution (used in mobileNet)
Inverse quantization
Direct Convolution 1x1
Direct Convolution 3x3
Direct Convolution 5x5
3D tensor flattening
Round down
Global pooling (used in SqueezeNet)
Leaky ReLu
Quantification
Reduction operation
ROI pooling
CPU (NEON):
Bounded ReLu
Direct Convolution 5x5
Inverse quantization
Round down
Leaky ReLu
Quantification
New function with fixed point acceleration
Direct convolution is an alternative to performing a convolutional layer on top of a classic sliding window. In the implementation of the Mali GPU Bifrost architecture, using Direct convolution is helpful in improving the performance of our CNN (we observed that performance can be up to 1.5 times faster when using Direct convolution for AlexNet).
Support low precisionIn many machine learning applications, efficiency and performance can be improved by reducing computational accuracy. This is the focus of our engineers in the last quarter. We implemented new versions of existing functions with low precision, such as 8-bit and 16-bit fixed points, which apply to both CPU and GPU.
GPU (OpenCL) - 8-bit fixed point
Direct Convolution 1x1
Direct Convolution 3x3
Direct Convolution 5x5
GPU (OpenCL) - 16-bit fixed point
Arithmetic addition, subtraction, and multiplication
Depth conversion
Deep connection (concatenate)
Deep convolution
GEMM
Convolution layer
Fully connected layer
Pooling layer
Softmax layer
NEON - 16-bit fixed point
Arithmetic addition, subtraction, and multiplication
Convolution layer
Deep connection (concatenate)
Depth conversion
Direct Convolution 1x1
Fully connected layer
GEMM
Softmax layer
Microarchitecture optimizationAt the beginning of the Compute Library project, our mission was to share a set of low-level functions for computer vision and machine learning. To ensure good performance, the most important thing is to be reliable and portable. Compute Library saves time and money for developers and partners looking at Arm processors; at the same time, Compute Library excels in many of the system configurations implemented by our partners. This is why we use NEONintrinsic and OpenCL C as our target languages. But in some cases, you must take full advantage of all the hardware's performance. Therefore, we also look at adding underlying primitives in the Compute Library that are optimized with manual assembly tailored to the target CPU microarchitecture.
When deciding which functions we should focus on, our R&D team studied machine learning workloads using the Caffe framework.
The three workloads used are:
AlexNet, classifying image targets into large networks of 1000 possible categories
LeNet, classifying handwritten numbers into medium-sized networks in 10 possible categories
ConvNet, classifying images into small networks of 10 possible categories
The following figure shows the instruction usage for these workloads:
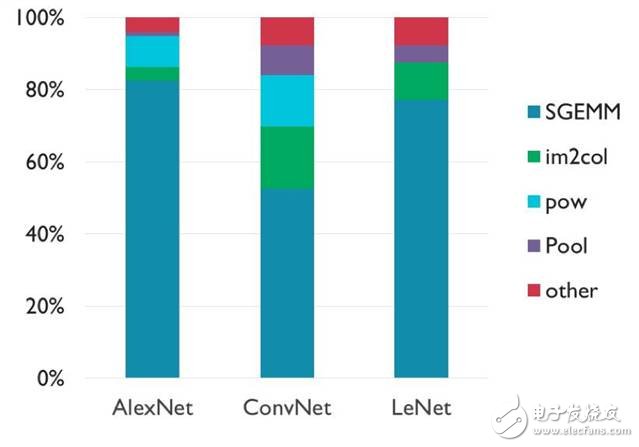
Our team found that approximately 50-80% of the calculations in these networks occur within the SGEMM function, which multiplies two floating-point matrices. There are several other functions that are also prominent, such as power functions and functions that transform matrix dimensions. The rest of the calculations are spread over a long tail distribution.
You can find a trend in which the proportion of SGEMM increases as the size of the network grows, but this trend is more likely due to the configuration of the layers, not the size. From this we can realize that matrix multiplication is really important for neural networks. If you say which objective function needs optimization most, it should be it.
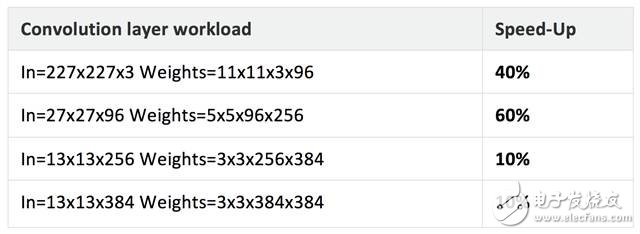
In this release of the library, we have added the CPU Assembly Optimized SGEMM (FP32) for the Cortex-A53 and Cortex-A72 processors. The performance of these routines varies from platform to platform, but we saw a significant increase in overall performance during testing. For example, we performed an AlexNet benchmark on the Firefly board (64-bit, multi-threaded), which measured a performance improvement of about 1.6 times on the Cortex-A72.
The table below shows a set of benchmark results for our use of the new optimization routines on the same platform.
In the introduction to the 17.6 release (the second public release of the Arm calculation library was officially released, these vendors have been using it for development!), Arm plans to support new architectural features for machine learning in the CPU, and the first step That is, FP16 is supported in the Armv8.2 CPU. Currently, the library has added a new function for the Armv8.2 FP16:
Activation layer
Arithmetic addition, subtraction, and multiplication
Batch Normalization
Convolutional layer (based on GEMM)
Convolutional layer (Direct convolution)
Local connection
Normalized
Pooling layer
Softmax layer
Although we did not make some radical optimizations for these functions (these functions were written in NEON intrinsic instead of hand-optimized assembly language), performance was significantly improved compared to using FP32 and having to convert between different formats. The table below compares some of the workloads, and it can be seen that with the v8.2 CPU instructions, you can reduce the number of cycles required for the calculation.

Today, many mobile partners are leveraging Mali GPUs to speed machine learning workloads. Based on feedback from these partners, we have made targeted optimizations in this area.
The new Direct convolutional 3x3 and 5x5 functions are optimized for the Bifrost architecture, and performance is significantly improved compared to the routines in the previous release (17.06). When using these new routines on some test platforms, we found that performance was generally improved by a factor of about 2.5. In addition, in AlexNet's multi-batch workloads, the new optimizations introduced in GEMM helped us achieve a 3.5x performance boost. Performance varies by platform and implementation, but overall, we expect these optimizations to significantly improve performance on Bifrost GPUs.
The following figure shows some of the test results on the Huawei Mate 9 smartphone. DVFS is disabled in the test and the shortest execution time of 10 runs is taken as the result. As you can see, the new routine is better than the old version in performance.

Complex workloads (large networks) will require a lot of memory, which is the crux of performance for both embedded and mobile platforms. We listened to the feedback from our partners and decided to add a "memory manager" function to the runtime components of the library. The memory manager reduces the memory requirements of the general algorithm/model by recycling the temporary buffer.
The memory manager contains a lifecycle manager (used to track the lifecycle of registered objects) and a pool manager (used to manage memory pools). When a developer configures a function, the runtime component tracks the memory requirements. For example, some tensors may be only temporary, so only the required memory is allocated. The memory manager configuration should be executed sequentially from a single thread to improve memory utilization.
The following table shows the memory savings measured on our test platform when using the Memory Manager. The results vary by platform, workload, and configuration. Overall, we believe that the memory manager can help developers save memory.


Next, we plan to continue to make specific optimizations based on the needs of our partners and developers. In addition, we will also focus on integration with machine learning frameworks and keep pace with new APIs such as Google Android NN.

Our goal is not to cover all data types and functions, but to select the functions that need to be implemented most based on feedback from developers and partners. So, we look forward to hearing from you!
The texture of Regular Back Sticker attracts you in a unique and innovative way. The ultra-thin and breathable material does not affect the heat dissipation function of the device at all. The smooth feel and personalized patterns not only protect the phone from scratches, dust, impacts and fingerprints. Bring you a different experience.
The Back Film protects the back cover of the phone from unnecessary scratches and repels dust, while reducing the signs of daily wear and tear.
It has oleophobic and waterproof effects, which can prevent the adhesion of oil stains and fingerprints. Provide comprehensive protection and maintain a new state.
Using the Protective Film Cutting Machine, you can install the Back Film on different types of mobile phone back shells, including mobile phones, tablets and other electronic products. With just one click, the customization can be completed in 30 seconds.
If you want to know more about Regular Back Sticker products, please click the product details to view the parameters, models, pictures, prices and other information about Regular Back Sticker products.
Whether you are a group or an individual, we will try our best to provide you with accurate and comprehensive information about Regular Back Sticke!
Leather Back Sticker, Aurora Back Sticker, Back Skin Sticker, Brushed Metal Back Sticker, Mobile Phone Sticker, Back Sticker,Mobile Skin Sticker
Shenzhen Jianjiantong Technology Co., Ltd. , https://www.morhoh-sz.com